凌晨两点,服务器报警响起——Nginx接口响应时间飙升300%。你盯着屏幕上密密麻麻的日志文件,手指在键盘上疯狂敲击grep "ERROR" .log,却只看到成百上千条重复的() 。这时候你才意识到:会用grep≠会分析日志。
在Lin...
awk f print 凌晨服务器报警!Nginx接口响应飙升,5个日志分析技巧助你捞针
凌晨两点,服务器报警响起——Nginx接口响应时间飙升300%。你盯着屏幕上密密麻麻的日志文件,手指在键盘上疯狂敲击grep "ERROR" .log,却只看到成百上千条重复的() 。这时候你才意识到:会用grep≠会分析日志。
在Linux运维的江湖里,日志是最诚实的“监控器”,但也是最容易被低估的“宝藏”。今天我们就跳出“查日志=关键词搜索”的误区,分享5个能让日志分析效率翻倍的实战技巧,帮你从“日志大海”里精准捞针。
技巧1:用awk替代grep,一行命令搞定统计
很多人习惯用grep -c "error" app.log统计错误次数,但如果需要更复杂的统计(比如按状态码分类、计算接口平均耗时),awk才是隐藏大佬。
举个真实场景:某电商大促时,API日志显示大量504 ,但需要快速定位是哪个后端服务拖后腿。这时候可以用:
awk '{print $9}' api.log | grep "504" | sort | uniq -c | sort -nr 其中$9对应HTTP状态码字段(需根据实际日志格式调整列号),这条命令能直接输出各状态码的出现次数,并按从高到低排序。如果日志包含时间戳,还能用awk截取时间段内的错误:
awk '/10\/Oct\/2023:14:00:/,/10\/Oct\/2023:14:30:/ {if ($9==504) print $0}' api.log 技巧2::系统日志的“万能遥控器”
很多人还在用cat /var/log/翻系统日志,但(自带工具)能让你像操作数据库一样管理日志。
技巧3::别让日志撑爆磁盘
日志文件无限增长是运维的“隐形炸弹”——某次我们线上服务器因.log占满200G磁盘,导致MySQL崩溃。这时候才想起(Linux自带的日志切割工具)。
默认情况下,每天运行一次(配置文件在/etc/.conf),但需要针对业务场景调整:
/var/log/nginx/access.log {
daily # 每天切割
rotate 7 # 保留7天旧日志
compress # 压缩旧日志(默认gzip)
missingok # 日志不存在不报错
notifempty # 空文件不切割
sharedscripts # 切割前后只执行一次脚本
postrotate
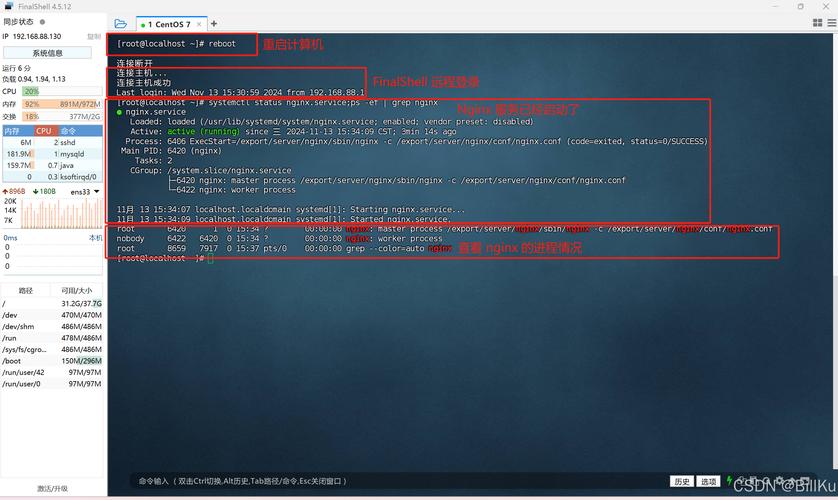
if [ -f /var/run/nginx.pid ]; then
kill -USR1 `cat /var/run/nginx.pid`
fi
endscript # 切割后通知Nginx重新生成日志文件
}关键提醒:修改配置后,手动触发切割测试: -vf /etc/.d/nginx(-v显示过程,-f强制执行)。
技巧4:grep的“隐藏技能”:正则表达式+上下文关联
grep远不止-c参数这么简单。比如,想找“接口超时但状态码正常”的日志(假设日志格式为 状态码 耗时),可以用正则表达式精准匹配:
grep -E '$.*$ /api/order [2-3][0-9]{2} [0-9]{6}' app.log 其中-E启用扩展正则,$.*$匹配任意接口路径,{2}限定状态码为2xx/3xx,{6}表示耗时超过1秒(假设单位是毫秒,6位数字即≥)。
如果需要查看错误前后的日志上下文,用-C参数:grep -C 5 "" app.log会显示错误行前后各5行的内容,快速定位问题链路。
技巧5:用zcat/zless处理压缩日志
生产环境的日志通常会被压缩成.gz格式,直接解压再分析太麻烦。这时候zcat(等价于 -c)和zless能让你直接“透视”压缩包里的内容:
zcat /var/log/nginx/access.log.1.gz | awk '{print $1}' | sort | uniq -c # 统计压缩日志中的IP访问量
zless /var/log/syslog.2.gz # 像用less一样分页查看压缩日志 实战案例:大促期间Nginx响应慢排查
上周大促时,我们遇到Nginx接口平均耗时从200ms飙升至1.5s。通过以下步骤快速定位:
实时监控: -u nginx -f发现大量() to :8080 错误。日志切割:确认.log未及时切割(配置的daily未生效,因磁盘空间不足),手动执行 -vf /etc/.d/nginx。统计分析:用awk '{print $NF}' .log | grep "1500" | wc -l统计耗时超过的请求数,发现集中在某个商品详情接口。溯源定位:结合后端服务的error.log(通过zcat查看压缩包),最终确认是数据库连接池耗尽导致超时。
写在最后:日志分析的本质是“用工具放大人类的观察力”。与其依赖“试错式排查”,不如掌握这些技巧,让日志成为你的“透视镜”。下次遇到线上故障时,不妨试试这些方法——你会发现,原来日志里藏着这么多“解题线索”。
#Linux#
日志 grep 切割 awk 技巧 var
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战
最近发表
-

2025淘宝新春开门红咋避价格管控?这些要点得知道
-

金秀贤择偶标准奇葩,原来因父母离婚缺爱
-

重庆富豪张松桥持续增持中渝置地 能提振股价吗?
-
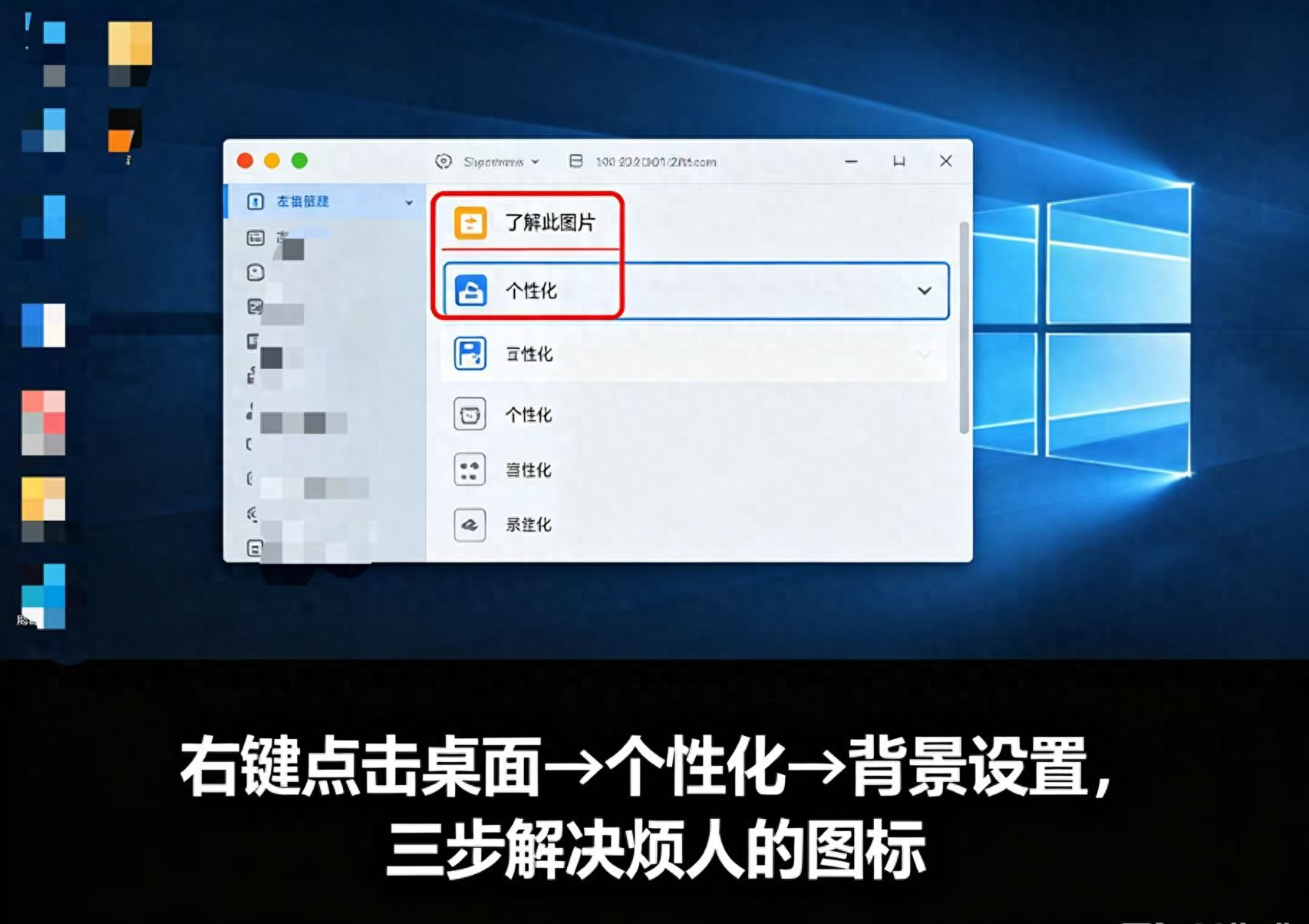
电脑无法粘贴?教你快速排查和解决常见原因
-

苹果6抹掉所有内容会怎样?恢复出厂后手机变快吗
-

金秀贤与已故金赛纶交往传闻反转,主播因假证据被逮捕
-

金秀贤父母离婚背后,16岁金赛纶的悲剧真相
-
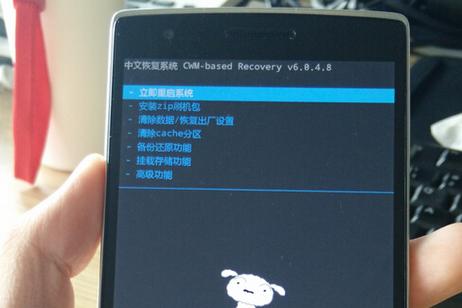
恢复出厂设置用英文怎么说?简单直译就是Restore Factory Settings
-

央视财经李斯璇:比撒贝宁还牛的学霸女主播
-

金秀贤父母离婚,恋童丑闻曝光:27岁男星与15岁少女6年恋情
-

金秀贤父母离婚内幕曝光 他崩溃痛哭真相揭秘
-
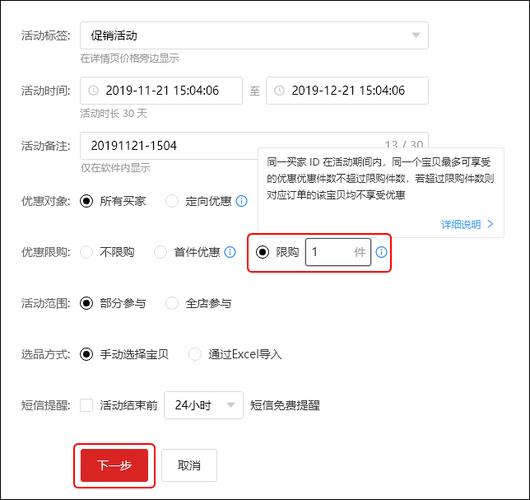
淘宝限购怎么办?多账号策略教你轻松避开关联