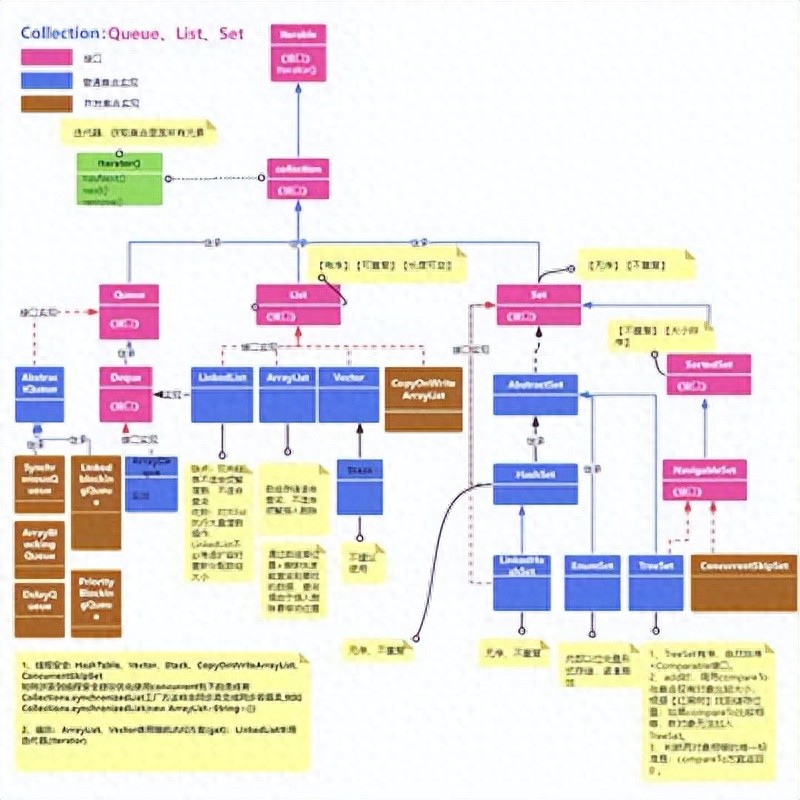
接口是所有集合框架的根接口,包括集合列表(List)、(Set)和队列(Queue)
接口
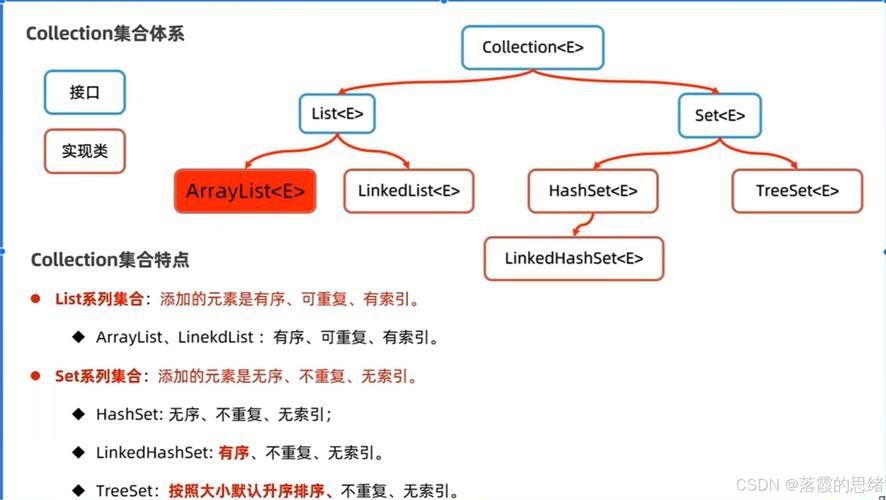
一、List接口是Java集合框架中的重要接口之一,它表示有序的集合,并且每个元素都有其索引,常见实现类介绍:
实现原理:
基于动态数组实现,...
queue.poll Java集合框架中List接口的ArrayList和LinkedList实现原理及应用场景
接口是所有集合框架的根接口,包括集合列表(List)、(Set)和队列(Queue)
接口
一、List接口是Java集合框架中的重要接口之一,它表示有序的集合,并且每个元素都有其索引,常见实现类介绍:
实现原理:
基于动态数组实现,能够快速访问任意位置的元素。其核心是一个数组,当数组空间不足时,会自动扩容。扩容是通过创建一个新的更大的数组,然后将原有数据复制到新数组中来实现的。
class ArrayList {
private int[] array;
private int size;
public ArrayList(int initialCapacity) {
array = new int[initialCapacity];
}
public E get(int index) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
return array[index];
}
public void add(E element) {
if (size == array.length) {
resize(); // 扩容操作
}
array[size] = element;
size++;
}
private void resize() {
int[] newArray = new int[array.length * 2]; // 扩容为原来的两倍
for (int i = 0; i < size; i++) {
newArray[i] = array[i]; // 复制原有数据到新数组
}
array = newArray; // 更新内部数组引用
}
} 使用场景:
适用于需要频繁访问元素的场景,如动态数组、列表等。
注意事项:
在添加和删除元素时可能会引起数组的扩容和复制,导致性能下降。特别是在删除元素时,可能需要移动大量元素来填补空缺,效率较低。
线程安全:
非线程安全。在多线程环境下使用时需要额外注意同步问题。
实现原理:
基于双向链表实现,每个节点包含前驱和后继节点的引用。链表结构允许在列表的头部和尾部进行高效插入和删除操作。
class LinkedListNode {
E data;
LinkedListNode prev;
LinkedListNode next;
}
class LinkedList {
private LinkedListNode head; // 头节点
private LinkedListNode tail; // 尾节点
private int size; // 链表大小
public E get(int index) {
// 实现省略...
}
public void add(E element) {
// 实现省略... (通常在尾部插入)
}
} 使用场景:
适用于需要在头部和尾部进行插入和删除操作的场景,如链表、队列等。
注意事项:
在中间插入和删除元素时效率较低,因为需要遍历链表找到合适的位置。
线程安全:
非线程安全。在多线程环境下使用时需要额外注意同步问题。
实现原理:
与类似,但它是同步的,是线程安全的。
class Vector {
private int[] array;
private int size;
private Object lock; // 用于同步的锁对象
public Vector(int initialCapacity) {
array = new int[initialCapacity];
lock = new Object(); // 创建一个锁对象
}
public synchronized E get(int index) {
// 实现省略...
}
public synchronized void add(E element) {
// 实现省略...
}
} 使用场景:
适用于需要在多线程环境下使用List的情况。但由于同步开销,性能可能较差。
注意事项:
与相比,的同步开销较大,性能较差。通常在需要线程安全但不追求极致性能的场景中使用。
实现原理:
的核心策略写时复制(Copy-on-Write)策略。当进行修改操作(如 add、set、 等)时,它会复制一个新的底层数组,然后在新的数组上进行修改操作。这种策略的好处是读操作不需要同步,因为读操作读取的是修改之前的数组副本。从而保证并发访问的安全性。读操作可以在多线程环境下安全地进行,而不需要额外的同步开销。写操作则会引起底层数组的复制,会有一定的性能影响。
import java.util.Arrays;
import java.util.List;
public class CopyOnWriteArrayList implements List {
private volatile Object[] array; // 底层数组
private final int modCount = 0; // 记录修改次数的变量
private static final long serialVersionUID = 8673269458301339658L;
private static final int DEFAULT_CAPACITY = 4; // 默认的初始容量
private static final Object[] EMPTY_ELEMENTDATA = {}; // 空数组
private static final Object[] SPARE_扩充数组大小
}
//当数组的长度超过当前数组的容量时,会进行数组扩容。
//扩容的过程比较简单,就是创建一个新的数组,长度为原来的两倍,
//然后将旧数组的元素复制到新数组中。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = array.length;
int newCapacity = oldCapacity << 1;
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity < 0) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
array = Arrays.copyOf(array, newCapacity);
}
//在 add、set、remove 等修改操作中,会先检查修改次数(modCount),
//如果 modCount 在进行修改操作前后发生了变化,说明有其他线程修改了列表,
//此时会抛出 ConcurrentModificationException。然后复制一个新的底层数组,
//长度比原数组多1(对于 add)或者少1(对于 remove),然后在新数组上进行修改操作。
//最后将新数组赋值给原数组,完成修改操作。
public boolean add(E e) {
Object[] a = array;
int s = size;
Object[] a = array; // read barrier establishing volatile-read order
if (s == a.length) {
grow();
a = array; // re-read after growth
}
a[s] = e; // invite concurrent readers to observe updated array contents
size = s + 1; // commit size update, see above block for explanation
modCount++; // signal possible readers and writers to retry their read-modify-write operations
return true;
} 使用场景:
适用于读多写少的并发场景,如读密集型的数据结构。这种数据结构在读操作远多于写操作时性能较好。
注意事项:
写操作可能会引起数组的复制,导致性能下降。因此,对于高并发的写密集型场景,可能不是最佳选择。
线程安全:
线程安全。在多线程环境下使用时无需额外的同步措施。
二、Set 接口在 Java 集合框架中表示一个不包含重复元素的集合,实现 Set 接口的一些常见集合类如下:
实现原理: 的核心是哈希表,它使用哈希函数将元素映射到桶中。每个桶包含一个链表,用于处理哈希冲突。元素的添加、删除和查找操作都基于哈希表进行。具体实现时, 使用了一个 Entry 数组来存储元素,每个 Entry 包含一个哈希码、一个元素值和指向下一个 Entry 的引用。在添加元素时,会计算元素的哈希码并找到对应的桶,然后将元素添加到链表中。查找操作也是通过计算元素的哈希码来快速定位到对应的桶,并在链表中查找元素。如果需要调整哈希表的大小, 会重新哈希现有元素到新的数组中。这个过程涉及到元素的重新计算哈希码和可能的链表重组。
public class HashSet extends AbstractSet {
// 哈希表,用于存储元素
private transient Entry[] table;
// 哈希表的大小(容量)
private int capacity = 101; // 初始容量
// 哈希表中的元素数量
private int size = 0;
// 哈希表中的元素
static class Entry implements Map.Entry {
// 元素的哈希码
final int hash;
// 元素的值
final E value;
// 下一个元素在哈希链表中的引用
Entry next;
// 构造函数
Entry(int hash, E value, Entry next) {
this.hash = hash;
this.value = value;
this.next = next;
}
// 其他方法...
}
// 构造函数,初始化哈希表大小和默认容量
public HashSet() {
table = new Entry[capacity];
}
// 其他方法...
} 使用场景:由于 不保证元素的顺序,它通常用于快速查找和删除操作。适用于存储大量数据且不需要频繁访问特定元素的场景。
注意事项:由于 依赖于哈希函数,如果哈希函数的质量差或者数据分布不均匀,性能会受到影响。另外,由于不保证元素的顺序,如果需要顺序访问元素,应考虑其他集合类型。
线程安全: 不是线程安全的。在多线程环境下使用时需要额外的同步措施。
实现原理: 是 的一个变种,它在内部使用哈希表和双向链表。除了通过哈希码定位元素外,还可以通过链表顺序访问元素。这使得 保持了插入顺序。双向链表用于维护元素的顺序。具体实现时, 使用了一个 Node 数组来存储元素,每个 Node 包含一个元素值和指向下一个 Node 的引用。在添加元素时,会计算元素的哈希码并找到对应的桶,然后将元素添加到链表中。同时,还会更新头尾节点和双向链表的连接关系。在迭代访问时,会按照链表的顺序遍历元素。如果需要调整哈希表的大小, 会重新哈希现有元素到新的数组中,同时重新构造双向链表。这个过程涉及到元素的重新计算哈希码、链表重组和调整头尾节点。
public class LinkedHashSet extends HashSet {
// 双向链表,用于维护元素的顺序
private transient Node first;
private transient Node last;
// 双向链表中的节点
static class Node {
E item; // 节点中的元素
Node next; // 下一个节点引用
Node before, after; // 前驱和后继节点的引用,用于迭代顺序
Node(Node b, Node n) { before = b; after = n; } // 构造函数,设置前驱和后继节点引用
}
// 构造函数,初始化链表头节点和尾节点
public LinkedHashSet() {
super();
first = new Node<>(null, null);
last = first;
}
// 其他方法...
} 使用场景:适用于需要快速查找、删除和保持插入顺序的场景。
注意事项:与 类似, 的性能也依赖于哈希函数的设计。此外,由于内部使用了链表,相对于 ,它有一些额外的内存开销。
线程安全: 不是线程安全的。
实现原理: 是基于红黑树实现的有序集合。红黑树是一种自平衡的二叉查找树,它通过颜色标记和旋转操作来维护树的平衡。 的实现利用了红黑树的特性,使得查找、插入和删除操作的时间复杂度接近 O(log n)。具体实现时, 使用了一个 Node 数组来存储元素,每个 Node 包含一个元素值和左右子节点引用。在添加元素时,会找到元素的插入位置并更新红黑树的结构。同时,还会更新最小节点引用。在查找元素时,会直接在红黑树中查找元素。如果需要调整红黑树的结构, 会执行相应的旋转和颜色调整操作。该过程涉及到节点的颜色标记和子节点的旋转操作。如果需要调整集合的大小, 会重新构建红黑树。该过程涉及到元素的重新排序和红黑树结构的调整。
public class TreeSet extends AbstractSet {
// 红黑树的根节点
private transient Node root;
// 最小节点,用于快速定位最小元素
private transient Node minNode;
// 集合的大小
private int size = 0;
// 红黑树的节点
static class Node {
E item; // 节点中的元素
Node left, right; // 左右子节点引用
int color; // 节点的颜色(红黑树的属性)
Node(E e, int color) { item = e; this.color = color; } // 构造函数,设置元素和颜色
}
// 构造函数,初始化红黑树根节点和最小节点引用
public TreeSet() {
root = null;
minNode = null;
}
// 其他方法...
} 
使用场景:适用于需要有序集合的场景,例如存储一组限制的数字或字符串等。
注意事项:使用 需要保证元素的排序性。如果元素类型没有实现 接口或没有提供 ,则无法使用 。此外,由于 是基于二叉查找树的,其性能在极端情况下可能不如基于哈希表的集合。
线程安全: 不是线程安全的。
实现原理: 是一个专门为枚举类型设计的 Set 集合。它使用位向量实现,每个枚举常量在内部表示为一个位标记。 的大小受限于枚举类型中常量的数量,因此不会像其他集合那样随着元素的增加而变慢。通过位操作快速判断元素是否属于集合。具体实现时, 使用了一个 int 数组来存储位向量。每个位表示一个枚举常量的状态,如果对应位为 1,表示该常量存在于集合中。通过位运算, 可以在常数时间内完成添加、删除和查找操作。
public final class EnumSet> extends AbstractSet {
// 枚举类型的 Class 对象
private final Class elementType;
// 位向量,用于存储枚举常量
private final int[] bits;
// 构造函数,根据枚举类型的枚举常量初始化位向量
EnumSet(Class type) {
elementType = type;
Bits.setSize(type.getEnumConstants().length);
bits = Bits.allocateBitArray();
Bits.setTo(bits, 0, type.getEnumConstants().length, false);
}
// 其他方法...
} 使用场景:适用于存储枚举类型的集合,特别是当集合的大小已知且不会太大时。
注意事项:由于 是为枚举类型设计的,它只能存储枚举类型的元素。此外,由于使用了位向量,如果枚举类型中的常量数量过多, 的性能可能会下降。
线程安全: 是线程安全的。
t
实现原理:t 是一个基于跳表的并发集合。跳表通过多级索引来提高查找性能。t 使用多个索引层来实现并发访问时的线程安全性。在每个索引层上,元素根据键的排序顺序进行排列。这使得 t 在插入、删除和查找操作上具有接近 O(log n) 的平均时间复杂度。具体的实现涉及多个类和方法,包括 、 等。t 的实现利用了分而治之的策略,通过多级索引来分割查找范围,并使用链表和红黑树来维护元素的存储和排序。通过多线程安全的锁机制实现并发访问,保证了线程安全性。
public class ConcurrentSkipListSet extends AbstractSet {
// 最大高度
private static final int MAX_HEIGHT = 16;
// 底层跳表的数组
private final Node[] nodes;
// 当前高度
private int height = 1;
// 集合的大小
private int size = 0;
// 跳表的节点
static class Node {
E item; // 节点中的元素
Node forward[]; // 下一个节点的引用数组
int level; // 节点所在的层级
Node(E e, int level) {
this.item = e;
this.level = level;
this.forward = new Node[level + 1];
}
}
// 构造函数,初始化跳表数组
public ConcurrentSkipListSet() {
nodes = new Node[MAX_HEIGHT];
}
// 其他方法...
} 使用场景:适用于高并发环境下的 Set 集合,需要保持元素的排序顺序。
注意事项:t 的内部实现相对复杂,因此在内存占用和性能方面需要谨慎考虑。此外,由于跳表的特性,其性能在极端情况下可能不如其他集合。
线程安全:t 是线程安全的。它提供了高性能的并发访问能力,适合在多线程环境下使用。
三、Queue接口的常见集合实现:
实现原理: 实现基于二叉堆( heap)数据结构
数组表示:二叉堆通常用数组来表示,其中父节点的位置 i 和其子节点的位置存在如下关系:左子节点位置为 2*i + 1,右子节点位置为 2*i + 2。这种表示方法使得堆的存储非常紧凑,并且父子节点的索引计算非常高效。堆属性:在最小堆中,每个节点都小于或等于其子节点。这个属性保证了堆顶元素总是最小的。添加元素:新元素被添加到数组的末尾,然后通过“上浮”( up)操作来恢复堆的属性。上浮操作是通过不断与父节点比较并交换位置来实现的,直到该元素不再小于其父节点或已经成为根节点。删除元素:通常删除的是堆顶元素(即最小元素)。删除后,数组的最后一个元素会被移到堆顶的位置,然后通过“下沉”(sink)操作来恢复堆的属性。下沉操作是通过不断与子节点比较并交换位置来实现的,直到该元素不再大于其子节点或已经成为叶子节点。动态数组:当数组空间不足时, 会自动扩容,通常是将当前数组大小加倍。
public class PriorityQueue extends AbstractQueue {
// 存储元素的数组
private transient Object[] queue;
// 队列大小
private int size;
// 比较器,如果为null则使用元素的自然顺序
private transient Comparator comparator;
// 修改计数器,用于快速失败行为
private transient int modCount = 0;
// 构造方法,指定初始容量和比较器
public PriorityQueue(int initialCapacity, Comparator comparator) {
if (initialCapacity < 1) {
throw new IllegalArgumentException();
}
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
// 添加元素到队列中
public boolean add(E e) {
return offer(e); // 方法别名,用于返回true(对于PriorityQueue总是true)
}
// 提供添加元素的方法,返回是否成功添加(对于PriorityQueue总是true)
public boolean offer(E e) {
if (e == null) {
throw new NullPointerException();
}
modCount++; // 修改计数器增加,用于快速失败行为
int i = size; // 获取当前队列大小
if (i >= queue.length) { // 如果队列已满,则扩容
grow(i + 1); // 扩容方法调用,增加队列容量
}
size = i + 1; // 设置新的队列大小值
if (i == 0) { // 如果队列为空,将元素放在索引0处(队列的根节点位置)
queue[0] = e; // 将元素放入队列数组中
} else { // 否则执行上浮操作,将新元素移到正确的位置以维持堆属性
siftUp(i, e); // siftUp私有方法实现上浮操作,通过比较和交换来维持最小堆属性
}
return true; // 对于PriorityQueue来说,添加操作总是成功(返回true)
}
... // 其他方法如siftUp, grow等实现细节略去...
} 使用场景:适用于元素的自然顺序有意义的场景,如任务调度或缓存管理。
注意事项:不支持访问最大或最小的元素,只能获取堆顶元素。
线程安全:不是线程安全的。
实现原理: 是 Java 并发包 java.util. 中的一个类,它是一个基于数组的有界阻塞队列
数据结构: 是一个线程安全的队列,它使用一个数组来存储元素。它有两个重要的成员变量:一个是数组 items 来存储元素,另一个是 count 来跟踪队列中的元素数量。阻塞机制:当队列满时,任何尝试添加元素的线程将会被阻塞,直到队列不满;同样,当队列为空时,任何尝试获取(或移除)元素的线程也会被阻塞,直到队列非空。FIFO原则: 遵循 FIFO(先进先出)原则。第一个进入队列的元素将是第一个被移除的元素。容量: 有一个初始容量和最大容量。当队列满了,并且已经达到最大容量时,再尝试添加元素将会抛出 n。
public class ArrayBlockingQueue extends AbstractQueue
implements BlockingQueue, java.io.Serializable {
// 存储元素的数组
private final ArrayDeque deque;
// 队列的最大容量
private final int capacity;
// 同步器,用于确保线程安全
private final ReentrantLock lock = new ReentrantLock();
// 用于在添加或删除元素时获取锁的内部锁对象
private final Condition queueCondition = lock.newCondition();
// 构造方法,指定初始容量和是否公平
public ArrayBlockingQueue(int capacity) {
this(capacity, false); // 第二个参数指定是否公平,这里设置为false表示非公平队列
}
// 构造方法,指定初始容量和公平性
public ArrayBlockingQueue(int capacity, boolean fair) {
this.capacity = capacity; // 设置队列的最大容量
this.deque = new ArrayDeque(capacity); // 初始化一个数组双端队列来存储元素
// 如果公平性为true,则使用基于 FIFO 的锁调度;否则使用基于最长时间未获取锁的线程的锁调度。
if (fair) {
lock.setFair(fair); // 设置锁的公平性
}
}
// 将元素添加到队列中,如果队列已满则阻塞等待空间可用或超时
public boolean add(E e) {
return offer(e); // 方法别名,用于返回true(对于BlockingQueue总是true)
}
// 提供添加元素的方法,返回是否成功添加(对于BlockingQueue总是true)
public boolean offer(E e) {
checkNotNull(e); // 检查元素是否为null,如果是则抛出NullPointerException异常
return innerOffer(e); // 将元素添加到队列中,如果成功则返回true,否则返回false并抛出异常
}
... // 其他方法如innerOffer, remove等实现细节略去...
} 使用场景:适用于生产者-消费者模式,特别是在多个生产者和消费者之间共享一个有限的缓冲区时。
注意事项:如果队列已满,尝试添加元素会导致阻塞;如果队列为空,尝试获取元素会导致阻塞。
线程安全:是线程安全的。它使用内部锁来确保并发访问的安全性。
实现原理: 是 Java 并发包 java.util. 中的另一个重要类,它是一个基于链表的阻塞队列
数据结构: 是一个基于链表的队列,它使用链表来存储元素。相比于基于数组的队列,链表队列在某些情况下可能更灵活,因为它们可以动态地调整大小。阻塞机制:当队列满时,任何尝试添加元素的线程将会被阻塞,直到队列不满;同样,当队列为空时,任何尝试获取(或移除)元素的线程也会被阻塞,直到队列非空。FIFO原则: 遵循 FIFO(先进先出)原则。第一个进入队列的元素将是第一个被移除的元素。容量: 有一个初始容量和最大容量。当队列满了,并且已经达到最大容量时,再尝试添加元素将会抛出 n。内存使用:与 不同, 可以根据需要动态地增加或减少其大小,这有助于更有效地使用内存。
public class LinkedBlockingQueue extends AbstractQueue
implements BlockingQueue, java.io.Serializable {
// 存储元素的链表
private final LinkedList queue;
// 队列的最大容量
private final int capacity;
// 同步器,用于确保线程安全
private final ReentrantLock lock = new ReentrantLock();
// 用于在添加或删除元素时获取锁的内部锁对象
private final Condition stackCondition = lock.newCondition();
// 构造方法,指定初始容量和是否公平
public LinkedBlockingQueue(int capacity) {
this(capacity, false); // 第二个参数指定是否公平,这里设置为false表示非公平队列
}
// 构造方法,指定初始容量和公平性
public LinkedBlockingQueue(int capacity, boolean fair) {
this.capacity = capacity; // 设置队列的最大容量
this.queue = new LinkedList(); // 初始化一个链表来存储元素
// 如果公平性为true,则使用基于 FIFO 的锁调度;否则使用基于最长时间未获取锁的线程的锁调度。
if (fair) {
lock.setFair(fair); // 设置锁的公平性
}
}
// 将元素添加到队列中,如果队列已满则阻塞等待空间可用或超时
public boolean add(E e) {
return offer(e); // 方法别名,用于返回true(对于BlockingQueue总是true)
}
// 提供添加元素的方法,返回是否成功添加(对于BlockingQueue总是true)
public boolean offer(E e) {
checkNotNull(e); // 检查元素是否为null,如果是则抛出NullPointerException异常
return innerOffer(e); // 将元素添加到队列中,如果成功则返回true,否则返回false并抛出异常
}
... // 其他方法如innerOffer, remove等实现细节略去...
} 使用场景:同样适用于生产者-消费者模式,尤其是需要具有较好吞吐量、元素非自然排序且删除操作不频繁的场景。
注意事项:与类似,如果队列已满,尝试添加元素会导致阻塞;如果队列为空,尝试获取元素会导致阻塞。
线程安全:是线程安全的。它使用内部锁来确保并发访问的安全性。
e
实现原理:e是一个线程安全的无界队列。它基于链接节点的无界非阻塞队列实现。
数据结构:e 是一个基于链表的队列。它使用一个链表来存储元素,并使用节点来存储数据。非阻塞:与 不同,e 是一个非阻塞队列。它不需要阻塞等待操作,而是通过原子操作和无锁算法来实现并发访问。FIFO原则:e 遵循 FIFO(先进先出)原则。第一个进入队列的元素将是第一个被移除的元素。容量:e 没有固定的容量限制,因为它基于链表实现,可以动态地增加或减少其大小。
public class ConcurrentLinkedQueue extends AbstractQueue {
// 存储元素的链表
private final Node head;
// 队列的大小
private int count;
// 用于在添加或删除元素时获取锁的内部锁对象
private final Node tail = new Node(); // 初始化一个尾节点作为队列的头部
// 构造方法
public ConcurrentLinkedQueue() {
head = new Node(); // 初始化一个头节点作为队列的尾部
}
// 将元素添加到队列中
public boolean add(E e) {
return offer(e); // 方法别名,用于返回true(对于BlockingQueue总是true)
}
// 提供添加元素的方法
public boolean offer(E e) {
final Node newNode = new Node(e); // 创建一个新节点来存储元素
final Node oldTail = tail.prev; // 获取当前尾节点的上一个节点
tail.setNext(newNode); // 将新节点设置为尾节点的下一个节点
newNode.setPrev(tail); // 将尾节点设置为新节点的上一个节点
count++; // 更新队列大小
if (oldTail == null) // 如果队列为空,将头节点设置为新节点
head.setNext(newNode);
else // 如果队列不为空,唤醒等待的线程(如果有)
oldTail.setNext(null); // 将旧尾节点的下一个节点设置为null,触发条件变量的通知操作
return true; // 返回true表示成功添加元素(对于BlockingQueue总是true)
}
... // 其他方法如remove, element等实现细节略去...
} 使用场景:适用于高并发、非阻塞的场景,如多线程任务调度或事件驱动系统。
注意事项:由于是无界的,因此在使用时需要特别小心,以避免内存溢出。
线程安全:是线程安全的。它使用无锁并发策略来确保并发访问的安全性。
实现原理:基于优先级队列实现,元素只有在其延迟期届满时才能从队列中检索到。具有延迟的取操作(直到特定延迟期间届满)。
数据结构: 是一个基于 的无界阻塞队列。它使用元素的延迟时间作为优先级。阻塞机制:当队列为空且尝试获取元素时,获取操作将会阻塞,直到有元素可以获取或者超时。同样,当尝试添加一个元素到已满的队列时,添加操作也会阻塞,直到队列不满或者超时。延迟时间: 中的元素只能在其延迟期结束时才能从队列中取走。元素的 () 方法返回剩余的延迟时间。
public class DelayQueue extends AbstractQueue {
// 存储元素的优先级队列
private final PriorityBlockingQueue queue = new PriorityBlockingQueue();
// 构造方法
public DelayQueue() { }
// 将元素添加到队列中,如果成功则返回true,否则返回false并抛出异常
public boolean offer(E e) {
return queue.offer(e); // 将元素添加到优先级队列中
}
// 从队列中获取元素,如果超时则返回null,否则返回元素并从队列中移除
public E take() throws InterruptedException {
return queue.take(); // 从优先级队列中获取元素并移除
}
... // 其他方法如poll, element等实现细节略去...
} 使用场景:适用于需要在特定延迟后才能处理元素的场景,例如缓存过期处理或延迟任务调度。
注意事项:不允许插入null元素。如果尝试插入null,将抛出。另外,无法检索具有指定元素的队列,只能检索并删除头部的元素或等待指定的延迟期届满。
线程安全:是线程安全的。它使用内部锁来确保并发访问的安全性。
实现原理:是一个不存储元素的阻塞队列。每个插入操作必须等待一个相应的删除操作,反之亦然。两个可以同时进行的操作必须通过彼此才能进行通信(通常是通过未来的中断方式)。
数据结构: 是一个没有存储空间的阻塞队列。它直接在尝试添加或移除元素时进行同步。阻塞机制:当队列为空且尝试获取元素时,获取操作将会阻塞,直到有元素可以获取或者超时。同样,当尝试添加一个元素到已满的队列时,添加操作也会阻塞,直到队列不满或者超时。容量:由于 没有存储空间,因此没有固定的容量限制。但是,由于它是阻塞队列,如果尝试添加或移除元素时没有其他线程正在进行相应的操作,则该操作将会阻塞。
public class SynchronousQueue extends AbstractQueue {
// 内部锁对象,用于同步操作
private final Object lock = new Object();
// 构造方法
public SynchronousQueue() { }
// 将元素添加到队列中,如果成功则返回true,否则返回false并抛出异常
public boolean add(E e) {
// 使用同步机制将元素添加到队列中
return offer(e); // 方法别名,用于返回true(对于BlockingQueue总是true)
}
// 从队列中获取元素,如果超时则返回null,否则返回元素并从队列中移除
public E take() throws InterruptedException {
// 使用同步机制从队列中获取并移除元素
return poll(); // 方法别名,用于返回非null元素(对于BlockingQueue总是非null)
}
... // 其他方法如offer, poll等实现细节略去...
} 使用场景:适用于完全在生产者和消费者之间同步的场景,例如线程池的工作队列。这种队列对于执行完全由另一个线程控制的同步任务特别有用。
注意事项:在所有尝试的操作中都表现出阻塞行为。
线程安全: 是线程安全的,它使用内部锁来确保在多线程环境下的操作原子性。
元素 节点 队列 线程 数组 操作
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战
最近发表
-

7月18日至19日昆明暴雨成灾,多地严重积水交通瘫痪
-
广州全力支持企业借香港资本市场优势融资发展
-

昆明雨季将至,实施防汛排涝清淤应急工程,预计5月31日完工
-

天津北剑之锋军事夏令营怎么样?费用多少?团队活动丰富吗?
-

北剑之锋军事夏令营培养孩子团队合作,拓展训练费用有多种选择
-

价值链管理挑战:突破传统,从物理现实与计算视角重构数智本体
-
queue.poll 常用消息队列框架介绍,含RabbitMQ、Kafka等使用方法
-

天使湾创投:专注互联网天使投资,简化申请流程,快速给反馈
-

2025年8月-2026年3月时事政治考点及题库汇总
-

聊军工股投资思路,行情下策略与执行力比基本面更重要
-
queue.poll Java集合框架中List接口的ArrayList和LinkedList实现原理及应用场景
-

电脑小白必看!五款能打开MP4文件的好用播放器推荐