什么是正则表达式
正则表达式是一种特殊的字符串模式,用于匹配一组字符串,就好比用模具做产品,而正则就是这个模具,定义一种规则去匹配符合规则的字符。
正则字符简单介绍元字符介绍
"^": ^会匹配行或者字符串的起始位置,有时还会匹配整个文档的...
正则表达式是什么?元字符、贪婪与懒惰量词介绍
什么是正则表达式
正则表达式是一种特殊的字符串模式,用于匹配一组字符串,就好比用模具做产品,而正则就是这个模具,定义一种规则去匹配符合规则的字符。
正则字符简单介绍元字符介绍
"^": ^会匹配行或者字符串的起始位置,有时还会匹配整个文档的起始位置.
"#34;: $会匹配行或字符串的结尾.
"\b": 不会消耗任何字符只匹配一个位置,常用于匹配单词边界 如 我想从字符串中"This is Regex"匹配单独的单词 "is" 正则就要写成 "\bis\b",\b 不会匹配is 两边的字符,但它会识别is 两边是否为单词的边界.
"\d": 匹配数字,例如要匹配一个固定格式的电话号码以0开头前4位后7位,如0737-5686123,正则:^0\d\d\d-\d\d\d\d\d\d\d$.
"\w": 匹配字母,数字,下划线,例如我要匹配"a2345BCD__TTz" 正则:"\w+",这里的"+"字符为一个量词指重复的次数.
"\s": 匹配空格,例如字符 "a b c" 正则:"\w\s\w\s\w" 一个字符后跟一个空格,如有字符间有多个空格直接把"\s" 写成 "\s+" 让空格重复.
".": 匹配除了换行符以外的任何字符,这个算是"\w"的加强版了"\w"不能匹配空格,如果把字符串加上空格用"\w"就受限了,看下用"."是如何匹配字符"a23 4 5 B C D__TTz" 正则:".+"
"[abc]": 字符组,匹配包含括号内元素的字符
几种反义
"\W" 匹配任意不是字母,数字,下划线 的字符
"\S" 匹配任意不是空白符的字符
"\D" 匹配任意非数字的字符
"\B" 匹配不是单词开头或结束的位置
"[^abc]" 匹配除了abc以外的任意字符
量词
贪婪(贪心),如"*"字符 贪婪量词会首先匹配整个字符串,尝试匹配时,它会选定尽可能多的内容,如果失败则回退一个字符,然后再次尝试回退的过程就叫做回溯,它会每次回退一个字符,直到找到匹配的内容或者没有字符可以回退。相比下面两种贪婪量词对资源的消耗是最大的.
懒惰(勉强),如 "?" 懒惰量词使用另一种方式匹配,它从目标的起始位置开始尝试匹配,每次检查一个字符,并寻找它要匹配的内容,如此循环直到字符结尾处.
占有,如"+" 占有量词会覆盖事个目标字符串,然后尝试寻找匹配内容,但它只尝试一次,不会回溯,就好比先抓一把石头,然后从石头中挑出黄金.
""(贪婪): 重复零次或更多,例如"",匹配字符串中所有的a,正则: "a",会出到所有的字符"a"
"+"(懒惰): 重复一次或更多次,例如"" 匹配字符串中所有的a,正则: "a+",会取到字符中所有的a字符,"a+"与"a*"不同在于"+"至少是一次而"*" 可以是0次.
"?"(占有): 重复零次或一次,例如"" 匹配字符串中的a,正则: "a?",只会匹配一次,也就是结果只是单个字符a.
"{n}": 重复n次,例如从"" 匹配字符串的a 并重复3次,正则: "a{3}"结果就是取到3个a字符"aaa";
"{n,m}": 重复n到m次,例如正则 "a{3,4}" 将a重复匹配3次或者4次,所以供匹配的字符可以是三个"aaa"也可以是四个"aaaa" 正则都可以匹配到.
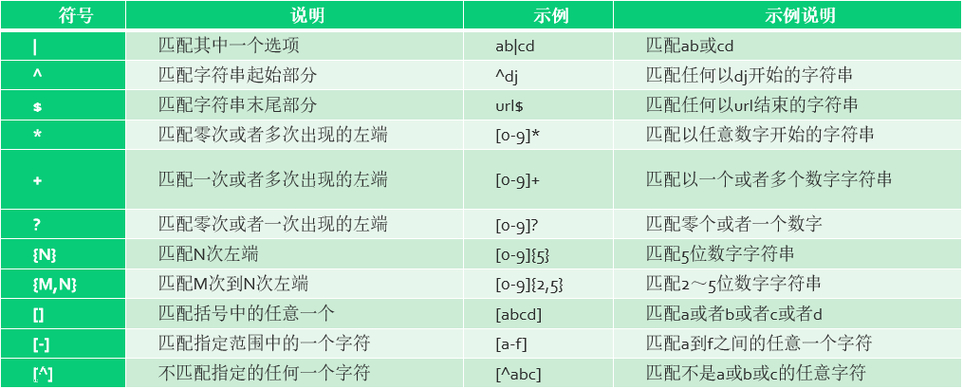
"{n,}": 重复n次或更多次,与{n,m}不同之处就在于匹配的次数将没有上限,但至少要重复n次 如 正则"a{3,}",a至少要重复3次
懒惰限定符
"?": 重复任意次,但尽可能少重复,例如"",正则"a.?b" 只会取到第一个"acb" 原本可以全部取到但加了限定符后,只会匹配尽可能少的字符,而""最少字符的结果就是"acb".
"+?": 重复1次或更多次,但尽可能少重复,与上面一样,只是至少要重复1次
"??": 重复0次或1次,但尽可能少重复,例如 "aaacb" 正则 "a.??b" 只会取到最后的三个字符"acb"
"{n,m}?": 重复n到m次,但尽可能少重复,例如 "" 正则 "a{0,m}" 因为最少是0次所以取到结果为空
"{n,}?": 重复n次以上,但尽可能少重复,例如 "" 正则 "a{1,}" 最少是1次所以取到结果为"a".
grep 正则表达式
grep ( (RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
grep常用用法
grep [-acinv] [--color=auto] '搜寻字符串' filename
选项与参数:
-a :将 binary 文件以 text 文件的方式搜寻数据
-c :计算找到 '搜寻字符串' 的次数
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行!
--color=auto :可以将找到的关键词部分加上颜色的显示喔!
sed 正则表达式sed 用法
# 批量替换
sed -i "s/oldstring/newstring/g" grep oldstring -rl pathawk 正则表达式awk 语法
awk `/REG/{action}`awk可以读取后接的文件,也可以读取来自前一命令的标准输入,它分别扫描输入数据的每一行,查找当前扫描行中是否匹配。如果匹配,则进行后续动作。如果不匹配或部分处理完毕,则继续处理下一行,直到结束。
awk '{
BEGIN{...} #执行前语句
pattern{...} #每一行都会处理的语句,可以有多个
END{...} #执行后要处理的语句
}'其中BEGIN为处理文本前的操作,一般用于改变FS,OFS,RS,ORS等,BEGIN部分完成之后,awk读取第一行输入,并将第一行的数据填入$0,$1,$2,..,$n,NR,NF等变量,然后进入正式处理阶段,待所有行处理完毕之后,进入END部分,END一般用于总结,打印报表等。
正式处理是一个内建的循环,每一次循环读取一行数据(默认RS为换行符),{...}部分可以有多个,它可以使用正则匹配/RE/,算术运算符>,
匹配 字符 正则 重复 字符串 grep
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战
最近发表
-

我的中国梦时事热点:航天梦70年,从蓝图到圆梦
-
券商子公司新规来了,证券投资管理更严了
-

我的中国梦:劳动最光荣,奋斗正当时
-

个人养老金怎么投?证监新规:公募基金投资管理细则
-

星际机甲传奇txt微盘 机甲爽文合集下载
-

吕良伟老婆杨小娟照片,北大毕业的女强人,难怪不带她回老家
-

政府新闻稿模板:写好政务信息,牢记四有诀窍
-
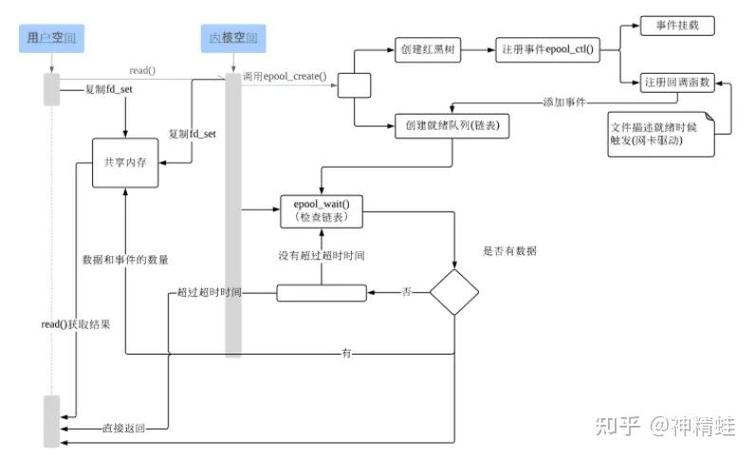
理解select和epoll原理,掌握流I/O操作及阻塞概念
-

武陟公安局李新功照片 真实身份曝光
-

盘点9.5分以上巅峰科幻小说,含星际机甲流佳作冒牌大英雄
-
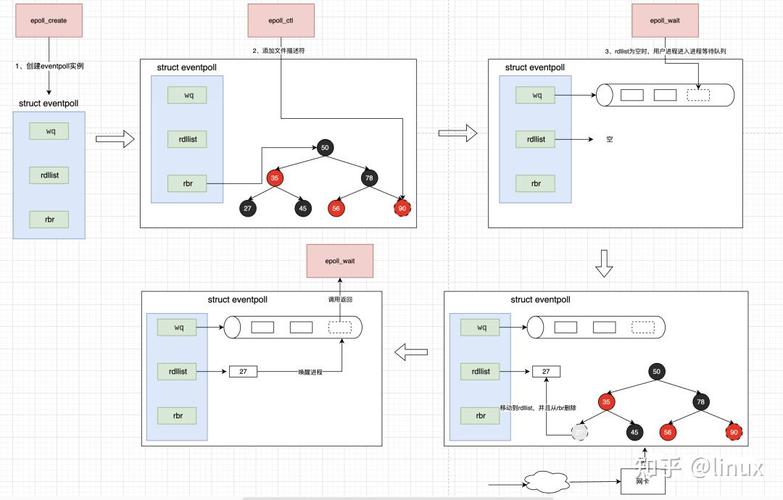
epoll、poll、select对比:I/O多路复用技术全解析及区别
-

Python女神讲师视频教程,长沙大学生周末零基础速成班实测