彻底搞懂epoll高效运行的原理
前言
这篇文章读不懂的没关系,可以先收藏一下。笔者准备介绍完epoll和NIO等知识点,然后写一篇Java网络IO模型的介绍,这样可以使Java网络IO的知识体系更加地完整和严谨。初学者也可以等看完IO模型...
epoll线程池高效原理,一篇文章彻底搞懂
彻底搞懂epoll高效运行的原理
前言
这篇文章读不懂的没关系,可以先收藏一下。笔者准备介绍完epoll和NIO等知识点,然后写一篇Java网络IO模型的介绍,这样可以使Java网络IO的知识体系更加地完整和严谨。初学者也可以等看完IO模型介绍的博客之后,再回头看这些博客,会更加有收获。
如果你顺利啃下这篇博客,恭喜你,nginx、redis和NIO等核心思想已经被你掌握了,可以顺势去拓展自己的理解。否则,只是孤立的看epoll,时间一长会很快忘记的。
当然,这些核心思想,笔者也会在之后的博客慢慢做详细讲解,欢迎关注
概念初探
epoll是一种I/O事件通知机制,是linux 内核实现IO多路复用的一个实现。
IO多路复用是指,在一个操作里同时监听多个输入输出源,在其中一个或多个输入输出源可用的时候返回,然后对其的进行读写操作。
IO多路复用,以后的博客会有详细讲解。
I/O
输入输出(input/)的对象可以是文件(file), 网络(),进程之间的管道(pipe)。在linux系统中,都用文件描述符(fd)来表示。
事件通知机制
通知机制,就是当事件发生的时候,则主动通知。通知机制的反面,就是轮询机制。
epoll的通俗解释
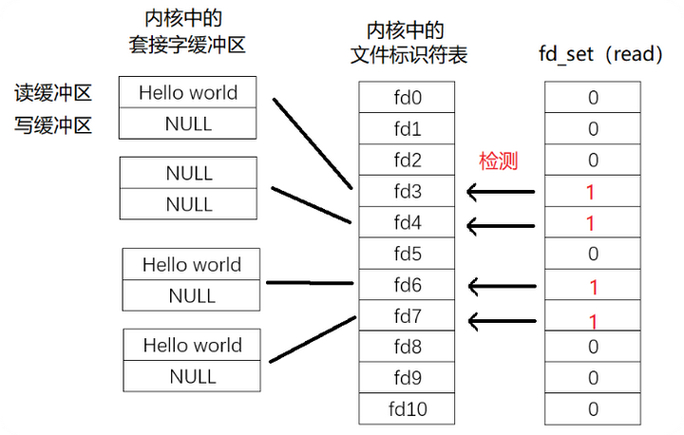
结合以上三条,epoll的通俗解释是一种当文件描述符的内核缓冲区非空的时候,发出可读信号进行通知,当写缓冲区不满的时候,发出可写信号通知的机制
epoll的API详解
epoll的核心是3个API,核心数据结构是:1个红黑树和1个链表
1. int (int size)
功能:
size参数表示所要监视文件描述符的最大值,不过在后来的Linux版本中已经被弃用(同时,size不要传0,会报 错误)
2. int (int epfd, int op, int fd, *event)
功能:
typedef union epoll_data {
void *ptr; /* 指向用户自定义数据 */
int fd; /* 注册的文件描述符 */
uint32_t u32; /* 32-bit integer */
uint64_t u64; /* 64-bit integer */
} epoll_data_t;
struct epoll_event {
uint32_t events; /* 描述epoll事件 */
epoll_data_t data; /* 见上面的结构体 */
};
对于需要监视的文件描述符集合,对红黑树进行管理,红黑树中每个成员由描述符值和所要监控的文件描述符指向的文件表项的引用等组成。
op参数说明操作类型:
结构描述一个文件描述符的epoll行为。在使用函数返回处于ready状态的描述符列表时,
常用的epoll事件描述如下:
3. int (int epfd, *, int , int );
功能:
处于ready状态的那些文件描述符会被复制进ready list中,用于向用户进程返回ready list。和两个参数描述一个由用户分配的 epoll event数组,调用返回时,内核将ready list复制到这个数组中,并将实际复制的个数作为返回值。注意,如果ready list比长,则只能复制前个成员;反之,则能够完全复制ready list。
另外, epoll event结构中的域在这里的解释是:在被监测的文件描述符上实际发生的事件。
参数描述在函数调用中阻塞时间上限,单位是ms:
epoll的两种触发方式
epoll监控多个文件描述符的I/O事件。epoll支持边缘触发(edge ,ET)或水平触发(level ,LT),通过等待I/O事件,如果当前没有可用的事件则阻塞调用线程。
和poll只支持LT工作模式,epoll的默认的工作模式是LT模式。
1.水平触发的时机对于读操作,只要缓冲内容不为空,LT模式返回读就绪。对于写操作,只要缓冲区还不满,LT模式会返回写就绪。
当被监控的文件描述符上有可读写事件发生时,()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用 ()时,它还会通知你在上没读写完的文件描述符上继续读写,当然如果你一直不去读写,它会一直通知你。如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率。
2.边缘触发的时机当缓冲区由不可读变为可读的时候,即缓冲区由空变为不空的时候。当有新数据到达时,即缓冲区中的待读数据变多的时候。当缓冲区有数据可读,且应用进程对相应的描述符进行 修改事件时。当缓冲区由不可写变为可写时。当有旧数据被发送走,即缓冲区中的内容变少的时候。当缓冲区有空间可写,且应用进程对相应的描述符进行 修改事件时。
当被监控的文件描述符上有可读写事件发生时,()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你。这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符。
在ET模式下, 缓冲区从不可读变成可读,会唤醒应用进程,缓冲区数据变少的情况,则不会再唤醒应用进程。
举例1:
读缓冲区刚开始是空的读缓冲区写入2KB数据水平触发和边缘触发模式此时都会发出可读信号收到信号通知后,读取了1KB的数据,读缓冲区还剩余1KB数据水平触发会再次进行通知,而边缘触发不会再进行通知
举例2:(以脉冲的高低电平为例)
JDK并没有实现边缘触发,Netty重新实现了epoll机制,采用边缘触发方式;另外像Nginx也采用边缘触发。
JDK在Linux已经默认使用epoll方式,但是JDK的epoll采用的是水平触发,而Netty重新实现了epoll机制,采用边缘触发方式,netty epoll 暴露了更多的nio没有的配置参数,如 , 等等;另外像Nginx也采用边缘触发。
epoll与、poll的对比1. 用户态将文件描述符传入内核的方式2. 内核态检测文件描述符读写状态的方式3. 找到就绪的文件描述符并传递给用户态的方式4. 重复监听的处理方式epoll更高效的原因和poll的动作基本一致,只是poll采用链表来进行文件描述符的存储,而采用fd标注位来存放,所以会受到最大连接数的限制,而poll不会。、poll、epoll虽然都会返回就绪的文件描述符数量。但是和poll并不会明确指出是哪些文件描述符就绪,而epoll会。造成的区别就是,系统调用返回后,调用和poll的程序需要遍历监听的整个文件描述符找到是谁处于就绪,而epoll则直接处理即可。、poll都需要将有关文件描述符的数据结构拷贝进内核,最后再拷贝出来。而epoll创建的有关文件描述符的数据结构本身就存于内核态中,系统调用返回时利用mmap()文件映射内存加速与内核空间的消息传递:即epoll使用mmap减少复制开销。、poll采用轮询的方式来检查文件描述符是否处于就绪态,而epoll采用回调机制。造成的结果就是,随着fd的增加,和poll的效率会线性降低,而epoll不会受到太大影响,除非活跃的很多。epoll的边缘触发模式效率高,系统不会充斥大量不关心的就绪文件描述符
虽然epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
哎呀,如果我的名片丢了。微信搜索“全菜工程师小辉”,依然可以找到我
最后编辑于 :2019.07.27 22:16:12
©著作权归作者所有,转载或内容合作请联系作者
【社区内容提示】社区部分内容疑似由AI辅助生成,浏览时请结合常识与多方信息审慎甄别。
epoll 描述 文件 通知 触发 缓冲区
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战
最近发表
-

理财故事:基金投教如何帮普通人赚到长期钱
-
电脑无法从U盘引导启动?先改BIOS再查U盘制作
-

如何做好信息安全?从骚扰电话看个人信息泄露维权
-

如何做好信息安全?5分钟搞定这5件事,保护个人数据安全
-

修改符号有哪些?教你用对modify、revise、amend、alter
-

普通人如何做好信息安全?云南网警教你防信息泄露
-

贯彻总书记指示精神,做好网络安全工作的总体目标与要点
-

学校演习变搞笑赛跑,学生跑丢方向笑翻全场
-

cmdb 外贸稳增显韧性,中国制造全球供应链优势凸显
-

学校元旦联欢搞笑新闻稿:老师们的才艺翻车现场
-

U盘装系统进不去引导?教你几招解决启动失败
-

学校搞笑新闻稿:开学典礼上校长讲段子,新生笑翻全场