2026年以来, AI + Multi-Agent 是Java圈最热的技术方向之一。不少团队开始在真实项目里落地多智能体架构,用来做智能客服、工单分诊、代码审查助手等场景。
但落地过程中,踩坑的团队比跑通的多。
有开发团队在上线 AI多Ag...
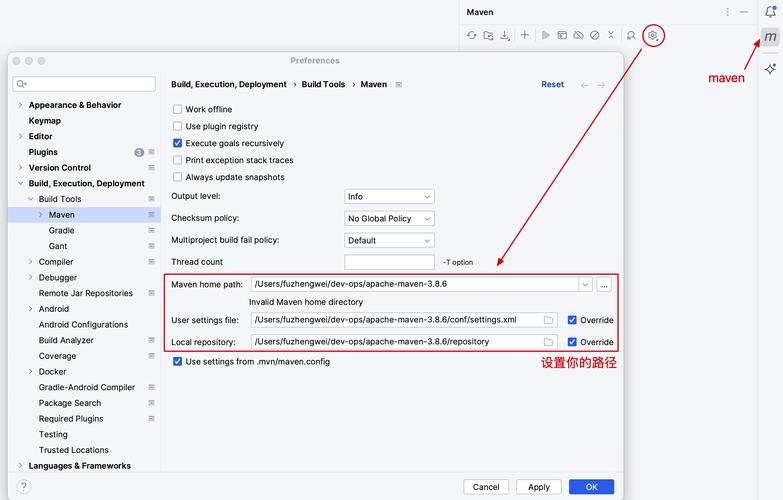
spring aop maven Spring AI多Agent踩坑:conversationId串话导致上下文污染,Maven项目这样排查
2026年以来, AI + Multi-Agent 是Java圈最热的技术方向之一。不少团队开始在真实项目里落地多智能体架构,用来做智能客服、工单分诊、代码审查助手等场景。
但落地过程中,踩坑的团队比跑通的多。
有开发团队在上线 AI多Agent系统后,排查了整整两天的异常,最终定位到三个高频坑。这三个坑在文档里几乎没有人系统总结,但每一个都可能让项目组花大量时间排查。
坑一:串话,多Agent上下文互相污染
这是最多团队第一个踩到的坑。
AI的机制,依赖来区分不同对话会话。如果多个 Agent共用了同一个,问题就出现了:不同Agent的对话历史会混在一起,导致后续输出结果不可预期。
真实场景是这样的:
// 错误写法:所有Agent共用同一个
.(, ); // 调度Agent
.(, ); // 技术支撑Agent
.(, ); // 销售Agent
结果:技术Agent的对话历史被销售Agent读取到,回复内容开始出现"您咨询的资费问题……"这种完全不相关的输出。用户问技术问题,得到的却是销售话术。
正确做法是给每个Agent的加唯一后缀:
// 正确写法:每个Agent使用独立的
.(, + "-orch");
.(, + "-tech");
.(, + "-sales");
这个坑的隐蔽之处在于:本地测试时,单轮对话几乎发现不了,只有多轮对话、多Agent协作场景下才会暴露。上线后用户反馈"回复乱七八糟",项目组才开始排查。
坑二:JVM内存记忆,服务重启后对话上下文全部丢失
AI默认使用ory,它将对话历史存在JVM内存中。这在开发环境没问题,但在生产环境是一个隐性地雷。
服务重启、容器重新调度、Pod滚动更新——任何一次重启,所有用户的对话上下文全部清空。用户正在跟智能客服聊到第三步,刷新页面后发现"您好,请问有什么可以帮您?"——上下文归零。
有团队在第一次灰度发布后就收到了用户投诉:
"我刚才说了三遍订单号,一刷新又让我重新报一遍。"
这个问题在开发环境几乎不可能发现,因为本地调试时服务一直开着。只有上到生产环境、经历第一次重启后,才会暴露。
正确做法是在生产环境使用Redis持久化存储对话记忆:
// 生产环境必须使用Redis持久化
// key格式:chat::{},建议设置7天过期
@Bean
( ) {
new ();
注意:这里需要自行实现, AI目前没有内置Redis实现,只提供了内存版本的ory。
坑三:LLM输出JSON格式不稳定,解析直接抛500
多Agent架构里,调度Agent()通常需要将用户意图解析为结构化JSON,再分发给对应 Agent。但LLM的输出格式并不稳定。
即使你在里明确要求"只输出JSON,不要包裹代码块",LLM仍然有一定概率返回如下内容:
// LLM的实际输出(开发者期望的是纯JSON)
```json
"": "",
"": 0.92
```
如果后端直接拿这个字符串去用解析,会直接抛ion,前端看到的就是500错误。
更隐蔽的问题是:这个错误不是必现的。有的query返回纯JSON,有的返回包裹的JSON,测试阶段很容易漏掉。
正确做法是在解析前做清理,并加降级逻辑:
// 第一步:清理代码块标记
= .("```json\\s*", "")
.("```\\s*", "");
// 第二步:加降级处理,解析失败不直接抛500
try {
plan = .(, .class);
plan;
} catch ( e) {
// 降级:直接拼接各Agent结果,并标记需人工介入
new ("", );
没有降级逻辑的多Agent系统,在LLM输出格式异常时,会直接把异常抛给用户。而有降级逻辑的系统,即使在极端情况下也能给出可用回复。
这三个坑的共性
它们有一个共同特点:在开发环境和单测里几乎发现不了,只有上了生产、有了真实流量和多轮对话后才会暴露。
这也是 AI多Agent落地最难的地方——Demo跑通容易,生产级别的稳定运行,需要踩过这些坑才能积累出经验。
一个判断: AI多Agent适合做AI应用层(智能客服、工单分诊、内容生成流程等)。但如果是做日常Java工程开发——写、、DAO层代码,处理映射、 Boot配置——用专为Java工程设计的AI工具,比自己搭多Agent流程要直接得多。
飞算智能体的思路:不做通用Agent,只做Java工程专属
多Agent架构适合需要"多个角色协作完成复杂任务"的场景。但Java工程师的日常开发,需要的不是"多个Agent开会讨论",而是:
这些是飞算聚焦的场景。它不试图做一个通用多Agent框架,而是把"Java工程代码生成"这件事做到极致——懂规范、懂映射、懂Maven依赖管理,生成的代码直接可运行,不需要人工大幅修正。
对于想尝试 AI多Agent的Java团队,建议先在小流量场景验证稳定性,把上述三个坑的防御逻辑都加上,再考虑全量上线。
一句话总结: AI多Agent是一个强大的方向,但落地生产环境需要绕过不少隐性坑。对于日常Java工程开发提效,选择专为Java生态设计的AI辅助工具,投入产出比通常更高。
Agent AI 对话 Java 直接 环境
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战
最近发表
-

cmdb CMDB+AI智能体可观测:企业选型避坑指南
-

小米电话手表使用说明:儿童手表选购关键点
-

U盘插上电脑无法启动?教你三步搞定BIOS设置和格式问题
-

2026企业选CMDB必看:一体化运维如何打通数据与流程
-
电脑无法从U盘引导启动?教你一步步排查设置问题
-

cmdb CMDB遇上告警风暴,一句话揪出根因事件
-
国美电器股票行情:黄光裕再减持,股价创低,投资者需警惕
-

cmdb CMDB救场:网络工程师别再单点抓包了,设备管理先搞清
-

长沙财经学校运动场怎么样?实地探访来了
-

长沙财经学校运动场 新生军训典礼震撼上演
-

大学生知识竞赛节目:湘台学子传统文化抢答赛,看谁更懂中国
-

cmdb CMDB运维实战:MTU故障排查两天,云原生环境避坑指南