Soup 4.12.0 文档
Soup 是一个可以从 HTML 或 XML 文件中提取数据的 库。它能用你喜欢的解析器和习惯的方式实现文档树的导航、查找、和修改。它会帮你节省数小时甚至数天的工作时间。
这篇文档介绍了 Soup 4...
beautifulsoup 爬虫 Beautiful Soup 4.12.0 文档:Python 库提取数据全解析
Soup 4.12.0 文档
Soup 是一个可以从 HTML 或 XML 文件中提取数据的 库。它能用你喜欢的解析器和习惯的方式实现文档树的导航、查找、和修改。它会帮你节省数小时甚至数天的工作时间。
这篇文档介绍了 Soup 4 中所有主要特性,并附带例子。文档会展示这个库的适合场景,工作原理,怎样使用,如何达到预期效果,以及如何处理异常情况。
文档覆盖了 Soup 4.12.0 版本,文档中的例子使用 3.8 版本编写。
你可能在寻找 Soup3的文档, Soup 3 目前已经停止开发,并且自 2020年12月31日以后就停止维护了。如果想要了解 Soup 3 和 Soup 4 的不同,参考 。
这篇文档已经被翻译成多种语言:
寻求帮助
如果有关于 Soup 4 的疑问,或遇到了问题,可以发送邮件到 。
如果问题中包含要解析的 HTML 代码,那么请在你的问题描述中附带这段HTML文档的 。
如果报告文档中的错误,请指出具体文档的语言版本。
快速开始
下面的一段HTML代码将作为例子被多次用到。这是 爱丽丝梦游仙境 的一段内容(以后简称 爱丽丝 的文档):
html_doc = """The Dormouse's story The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie, Lacie and Tillie; and they lived at the bottom of a well....
"""
上面的 爱丽丝 文档经过 Soup 的解析后,会得到一个 的对象,一个嵌套结构的对象:
from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc, 'html.parser') print(soup.prettify()) # # #</span> <span class="c1"># The Dormouse's story</span> <span class="c1"># # # # # # The Dormouse's story # # # # Once upon a time there were three little sisters; and their names were # # Elsie # # , # # Lacie # # and # # Tillie # # ; and they lived at the bottom of a well. # # # ... # # #
这是几个简单的浏览结构化数据的方法:
soup.title #The Dormouse's story soup.title.name # u'title' soup.title.string # u'The Dormouse's story' soup.title.parent.name # u'head' soup.p #The Dormouse's story
soup.p['class'] # u'title' soup.a # Elsie soup.find_all('a') # [Elsie, # Lacie, # Tillie] soup.find(id="link3") # Tillie
常见任务之一,就是从文档中找到所有 标签的链接:
for link in soup.find_all('a'): print(link.get('href')) # http://example.com/elsie # http://example.com/lacie # http://example.com/tillie
另一种常见任务,是从文档中获取所有文字内容:
print(soup.get_text()) # The Dormouse's story # # The Dormouse's story # # Once upon a time there were three little sisters; and their names were # Elsie, # Lacie and # Tillie; # and they lived at the bottom of a well. # # ...
这是你想要的吗?是的话,继续看下去。
安装 Soup
如果你用的是新版的 或 ,那么可以通过系统的软件包管理来安装:
$ apt-get -bs4
Soup 4 通过 PyPi 发布,所以如果无法使用系统包管理安装,那么也可以通过 或 pip 来安装。包的名字是 。确保使用的是与 版本对应的 pip 或 版本(他们的名字也可能是 pip3 和 )。
$
$ pip
(在 PyPi 中还有一个名字是 的包,但那可能不是你想要的,那是 Soup3 版本。因为很多项目还在使用BS3, 所以 包依然有效。但是新项目中,应该安装 。)
如果没有安装 或 pip ,那也可以 下载 BS4 的源码 ,然后通过 setup.py 来安装。
$ setup.py
如果上述安装方法都行不通,根据 Soup 的协议,可以将项目的代码打包在你的项目中,这样无须安装即可使用。
Soup 用 3.10 版本开发,但也可以在当前的其它版本中运行。
安装解析器
Soup 支持 标准库中的 HTML 解析器,还支持一些第三方的解析器,其中一个是 lxml 。根据安装方法的不同,可以选择下列方法来安装 lxml:
$ apt-get -lxml
$ lxml
$ pip lxml
另一个可供选择的解析器是纯 实现的 , 的解析方式与浏览器相同,根据安装方法的不同,可以选择下列方法来安装:
$ apt-get -
$
$ pip
下表描述了几种解析器的优缺点:
解析器
使用方法
优势
劣势
- 的内置标准库
- 执行速度较快
- 容错能力强
- 速度没有 lxml 快,容错没有 强
lxml HTML 解析器
- 速度快
- 容错能力强
- 额外的 C 依赖
lxml XML 解析器
- 速度快
- 唯一支持 XML 的解析器
- 额外的 C 依赖
- 最好的容错性
- 以浏览器的方式解析文档
- 生成 HTML5 格式的文档
- 速度慢
- 额外的 依赖
如果可以,推荐使用 lxml 来获得更高的速度。
注意,如果一段文档格式不标准,那么在不同解析器生成的 Soup 数可能不一样。查看 了解更多细节。
如何使用
解析文档是,将文档传入 的构造方法。也可以传入一段字符串或一个文件句柄:
from bs4 import BeautifulSoupwith open("index.html") as fp: soup = BeautifulSoup(fp, 'html.parser') soup = BeautifulSoup("a web page", 'html.parser')
首先,文档被转换成 ,并且 HTML 中的实体也都被转换成 编码
print(BeautifulSoup("Sacré bleu!", "html.parser")) # Sacré bleu!
然后, Soup 选择最合适的解析器来解析这段文档。如果指定了解析器那么 Soup会选择指定的解析器来解析文档。(参考 )。
对象的种类
Soup 将复杂的 HTML 文档转换成一个复杂的由 对象构成的树形结构,但处理对象的过程只包含 4 种类型的对象: Tag, ,, 和 。
对象与 XML 或 HTML 原生文档中的 tag 相同:
soup = BeautifulSoup('Extremely bold', 'html.parser') tag = soup.b type(tag) #
Tag有很多属性和方法,在 和 中有详细解释。现在介绍一下 tag 中最重要的属性: name 和 。
bs4.name
每个 tag 都有一个名字:
tag.name # u'b'
如果改变了 tag 的 name,那将影响所有通过当前 Soup 对象生成的HTML文档:
tag.name = "blockquote" tag #Extremely bold
bs4.attrs
一个 HTML 或 XML 的 tag 可能有很多属性。tag id=""> 有一个 “id” 的属性,值为 “”。你可以想处理一个字段一样来处理 tag 的属性:
tag = BeautifulSoup('bold', 'html.parser').b tag['id'] # 'boldest'
也可以直接”点”取属性,比如: .attrs :
tag.attrs # {u'class': u'boldest'}
tag 的属性可以被添加、删除或修改。再说一次,tag的属性操作方法与字典一样
tag['id'] = 'verybold' tag['another-attribute'] = 1 tag # del tag['id'] del tag['another-attribute'] tag # bold tag['id'] # KeyError: 'id' tag.get('id') # None
多值属性
HTML 4 定义了一系列可以包含多个值的属性。在 HTML5 中移除了一些,却增加更多。最常见的多值的属性是 class (一个 tag 可以有多个 CSS class)。还有一些属性 rel、 rev、 -、 、 。默认情况, Soup 中将多值属性解析为一个列表:
css_soup = BeautifulSoup('', 'html.parser')
css_soup.p['class']
# ['body']
css_soup = BeautifulSoup('', 'html.parser')
css_soup.p['class']
# ['body', 'strikeout']
If an attribute `looks` like it has more than one value, but it's not
a multi-valued attribute as defined by any version of the HTML
standard, Beautiful Soup will leave the attribute alone::
id_soup = BeautifulSoup('', 'html.parser')
id_soup.p['id']
# 'my id'
如果某个属性看起来好像有多个值,但在任何版本的 HTML 定义中都没有将其定义为多值属性,那么 Soup 会将这个属性作为单值返回
id_soup = BeautifulSoup('', 'html.parser') id_soup.p['id'] # 'my id'
将 tag 转换成字符串时,多值属性会合并为一个值
rel_soup = BeautifulSoup('Back to the homepage
', 'html.parser') rel_soup.a['rel'] # ['index', 'first'] rel_soup.a['rel'] = ['index', 'contents'] print(rel_soup.p) #Back to the homepage
若想强制将所有属性当做多值进行解析,可以在 构造方法中设置tes=None 参数:
no_list_soup = BeautifulSoup('', 'html.parser', multi_valued_attributes=None) no_list_soup.p['class'] # 'body strikeout'
或者使用 方法来获取多值列表,不管是不是一个多值属性:
id_soup.p.get_attribute_list('id') # ["my id"]
如果以 XML 方式解析文档,则没有多值属性:
xml_soup = BeautifulSoup('', 'xml') xml_soup.p['class'] # 'body strikeout'
但是,可以通过配置 tes 参数来修改:
class_is_multi= { '*' : 'class'} xml_soup = BeautifulSoup('', 'xml', multi_valued_attributes=class_is_multi) xml_soup.p['class'] # ['body', 'strikeout']
可能实际当中并不需要修改默认配置,默认采用的是 HTML 标准:
from bs4.builder import builder_registry builder_registry.lookup('html').DEFAULT_CDATA_LIST_ATTRIBUTES
.
可遍历的字符串
字符串对应 tag 中的一段文本。 Soup 用 类来包装 tag 中的字符串:
soup = BeautifulSoup('Extremely bold', 'html.parser') tag = soup.b tag.string # 'Extremely bold' type(tag.string) #
一个 对象与 中的 字符串相同,并且还支持包含在 和 中的一些特性。通过 str 方法可以直接将 对象转换成 字符串:
unicode_string = str(tag.string) unicode_string # 'Extremely bold' type(unicode_string) #
tag 中包含的字符串不能直接编辑,但是可以被替换成其它的字符串,用 方法:
tag.string.replace_with("No longer bold") tag #No longer bold
对象支持 和 中定义的大部分属性,并非全部。尤其是,一个字符串不能包含其它内容(tag 能够包含字符串或是其它 tag),字符串不支持. 或 . 属性或 find() 方法。
如果想在 Soup 之外使用 对象,需要调用 ()方法,将该对象转换成普通的字符串,否则就算 Soup 方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
.
对象表示的是一个文档的全部内容。大部分时候,可以把它当作 Tag 对象,它支持 和 中描述的大部分的方法。
因为 对象并不是真正的HTML或XML的tag,所以它没有name和属性。但有时查看它的 .name 属性是很方便的,所以 对象包含了一个值为 “” 的特殊属性 .name
soup.name # u'[document]'
注释及特殊字符串
Tag, , 几乎覆盖了html和xml中的所有内容,但是还有一些特殊对象。容易让人担心的内容是文档的注释部分:
markup = "" soup = BeautifulSoup(markup, 'html.parser') comment = soup.b.string type(comment) #
对象是一个特殊类型的 对象:
comment # u'Hey, buddy. Want to buy a used parser'
但是当它出现在 HTML 文档中时, 对象会使用特殊的格式输出:
print(soup.b.prettify()) # # #
针对 HTML 文档
Soup 定义了一些 子类来处理特定的 HTML 标签。通过忽略页面中表示程序指令的字符串,可以更容易挑出页面的 body 内容。(这些类是在 Soup 4.9.0 版本中添加的, 解析器不会使用它们)
.
有一种 子类表示嵌入的 CSS 脚本;内容是 标签内部的所有字符串。
.
有一种 子类表示嵌入的 脚本;内容是
tag 文档 Soup 解析 属性 对象
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战
最近发表
-

cmdb CMDB+AI智能体可观测:企业选型避坑指南
-

小米电话手表使用说明:儿童手表选购关键点
-

U盘插上电脑无法启动?教你三步搞定BIOS设置和格式问题
-

2026企业选CMDB必看:一体化运维如何打通数据与流程
-
电脑无法从U盘引导启动?教你一步步排查设置问题
-

cmdb CMDB遇上告警风暴,一句话揪出根因事件
-
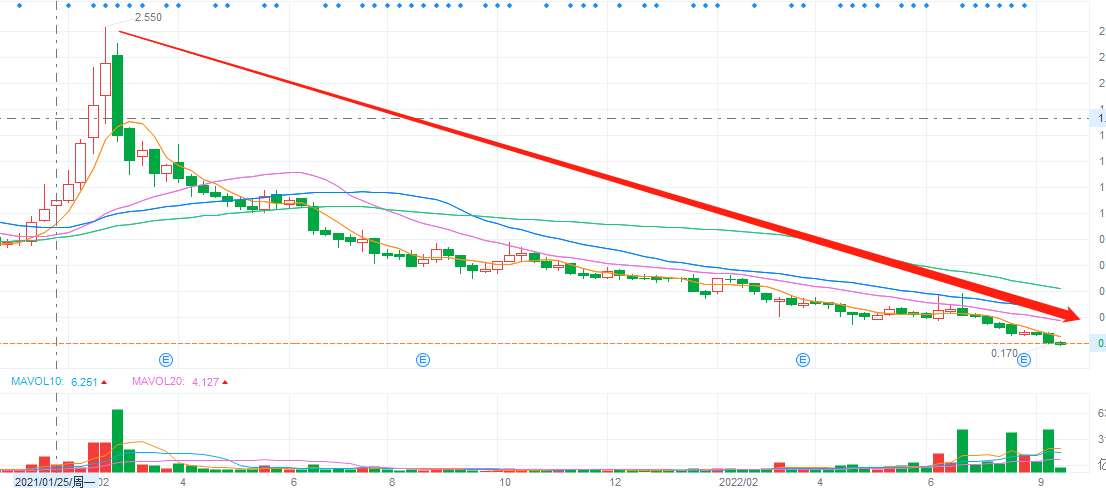
国美电器股票行情:黄光裕再减持,股价创低,投资者需警惕
-

cmdb CMDB救场:网络工程师别再单点抓包了,设备管理先搞清
-

长沙财经学校运动场怎么样?实地探访来了
-

长沙财经学校运动场 新生军训典礼震撼上演
-

大学生知识竞赛节目:湘台学子传统文化抢答赛,看谁更懂中国
-

cmdb CMDB运维实战:MTU故障排查两天,云原生环境避坑指南